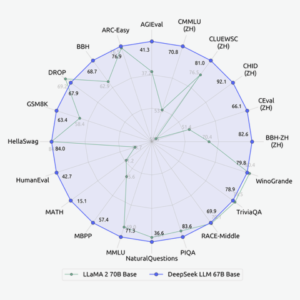
ARC-Easy – AI2 Reasoning Challenge, Easy Level: A dataset of grade-school level, multiple-choice science questions designed to evaluate the reasoning abilities of AI systems. AGIEval – Might refer to an AI General Intelligence Evaluation, but the specific evaluation or task is not universally recognized under this acronym. CMM LU (ZH) – Could be referring to a Chinese language evaluation task for machine understanding, but “CMM LU” isn’t a widely recognized standard acronym. “ZH” indicates the task is in Chinese. CLUEWSC (ZH) – CLUE (Chinese Language Understanding Evaluation) WSC (Winograd Schema Challenge): A natural language processing benchmark for Chinese, focusing on pronoun disambiguation. CHID (ZH) – Chinese IDiom dataset: Used for evaluating language understanding in tasks that involve idiomatic expressions in Chinese. CEval (ZH) – Likely refers to another Chinese Evaluation dataset, perhaps focusing on general language comprehension. BBH-ZH (ZH) – Not a standard acronym; could be specific to the study or dataset used in this particular evaluation. WinoGrande – A large-scale dataset for solving Winograd Schema Challenge-style problems, designed to test common sense reasoning. DROP – Discrete Reasoning Over the content of Paragraphs: A dataset that requires discrete reasoning over a paragraph of text. GSM8K – Grade School Math 8K Dataset: A collection of math word problems intended for evaluating arithmetic and algebraic reasoning. HellaSwag – A dataset for testing common sense story completion, which asks models to choose the most likely continuation of a story. HumanEval – A benchmark for evaluating code synthesis models based on human-written coding problems. MATH – A collection of high school math problems used for evaluating mathematical reasoning in models. MBPP – Most Likely refers to the “Massive Boolean Program Performance” dataset or similar; specifics may vary depending on the context. MMLU – Multi-tasking Machine Learning Understanding or Massive Multitask Language Understanding: A general-purpose evaluation for language models across various domains. NaturalQuestions – A dataset for evaluating models on real, naturally occurring questions in a web search context. PIQA – Physical Interaction Question Answering: A benchmark for assessing a model’s understanding of physical world dynamics through question answering. RACE-Middle – Reading Comprehension Dataset, Middle School level: A collection of passages and questions used to evaluate reading comprehension. TriviaQA – A dataset consisting of trivia questions and answers used to test a model’s ability to retrieve and understand factual information.